






代码之丑(一)
“写代码”有两个维度:正确性和可维护性,不要只关注正确性。能把代码写对,是每个程序员的必备技能,但能够把代码写得更具可维护性,这是一个程序员从业余迈向职业的第一步。
本篇文章整理至郑烨老师《代码之丑》。
代码之丑音频-点我跳转
访问密码:WFjfq
缺乏业务含义的命名:如何精准命名?
不精准的命名
我们先来看一段代码:
public void processChapter(long chapterId) {
// 根据章节ID查询章节
Chapter chapter = this.repository.findByChapterId(chapterId);
if (chapter == null) {
throw new IllegalArgumentException("Unknown chapter [" + chapterId + "]");
}
// 将章节的翻译状态改为翻译中
chapter.setTranslationState(TranslationState.TRANSLATING);
this.repository.save(chapter);
}
这是一段看上去还挺正常的代码,甚至以很多团队的标准来看,这段代码写得还不错。但如果我问你,这段代码是做什么的。你就需要调动全部注意力,去认真阅读这段代码,找出其中的逻辑。经过阅读我们发现,这段代码做的就是把一个章节的翻译状态改成翻译中。
问题来了,为什么你需要阅读这段代码的细节,才能知道这段代码是做什么的?
问题就出在函数名上。这个函数的名字叫 processChapter(处理章节),这个函数确实是在处理章节,但是,这个名字太过宽泛。如果说“将章节的翻译状态改成翻译中”叫做处理章节,那么“将章节的翻译状态改成翻译完”是不是也叫处理章节呢?“修改章节内容”是不是也叫处理章节呢?换句话说,如果各种场景都能够叫处理章节,那么处理章节就是一个过于宽泛的名字,没有错,但不精准。
这就是一类典型的命名问题,从表面上看,这个名字是有含义的,但实际上,它并不能有效地反映这段代码的含义。如果说我在做的是一个信息处理系统,你根本无法判断,我做是一个电商平台,还是一个图书管理系统,从沟通的角度看,这就不是一个有效的沟通。要想理解它,你需要消耗大量认知成本,无论是时间,还是精力。
命名过于宽泛,不能精准描述,这是很多代码在命名上存在的严重问题,也是代码难以理解的根源所在。
或许这么说你的印象还是不深刻,我们看看下面这些词是不是经常出现在你的代码里:data、info、flag、process、handle、build、maintain、manage、modify 等等。这些名字都属于典型的过于宽泛的名字,当这些名字出现在你的代码里,多半是写代码的人当时没有想好用什么名字,就开始写代码了。我相信,只要稍微仔细想想,类似的名字你一定还能想出不少来。
回到前面那段代码上,如果它不叫“处理章节”,那应该叫什么呢?首先,命名要能够描述出这段代码在做的事情。这段代码在做的事情就是“将章节修改为翻译中”。那是不是它就应该叫 changeChapterToTranlsating 呢?
不可否认,相比于“处理章节”,changeChapterToTranlsating 这个名字已经进了一步,然而,它也不算是一个好名字,因为它更多的是在描述这段代码在做的细节。我们之所以要将一段代码封装起来,一个重要的原因就是,我们不想知道那么多的细节。如果把细节平铺开来,那本质上和直接阅读代码细节差别并不大。
所以,一个好的名字应该描述意图,而非细节。
就这段代码而言, 我们为什么要把翻译状态修改成翻译中,这一定是有原因的,也就是意图。具体到这里的业务,我们把翻译状态修改成翻译中,是因为我们在这里开启了一个翻译的过程。所以,这段函数应该命名 startTranslation。
public void startTranslation(long chapterId) {
Chapter chapter = this.repository.findByChapterId(chapterId);
if (chapter == null) {
throw new IllegalArgumentException("Unknown chapter [" + chapterId + "]");
}
chapter.setTranslationState(TranslationState.TRANSLATING);
this.repository.save(chapter);
}
用技术术语命名
List<Book> bookList = service.getBooks();
可以说这是一段常见得不能再常见的代码了,但这段代码却隐藏另外一个典型得不能再典型的问题:用技术术语命名。
这个 bookList 变量之所以叫 bookList,原因就是它声明的类型是 List。这种命名在代码中几乎是随处可见的,比如 xxxMap、xxxSet。这是一种不费脑子的命名方式,但是,这种命名却会带来很多问题,因为它是一种基于实现细节的命名方式。
我们都知道,编程有一个重要的原则是面向接口编程,这个原则从另外一个角度理解,就是不要面向实现编程,因为接口是稳定的,而实现是易变的。虽然在大多数人的理解里,这个原则是针对类型的,但在命名上,我们也应该遵循同样的原则。为什么?我举个例子你就知道了。
比如,如果我发现,我现在需要的是一个不重复的作品集合,也就是说,我需要把这个变量的类型从 List 改成 Set。变量类型你一定会改,但变量名你会改吗?这还真不一定,一旦出现遗忘,就会出现一个奇特的现象,一个叫 bookList 的变量,它的类型是一个 Set。这样,一个新的混淆就此产生了。
那有什么更好的名字吗?我们需要一个更面向意图的名字。其实,我们在这段代码里真正要表达的是拿到了一堆书,所以,这个名字可以命名成 books。
List<Book> books = service.getBooks();
也许你发现了,这个名字其实更简单,但从表意的程度上来说,它却是一个更有效的名字。
虽然这里我们只是以变量为例说明了以技术术语命名存在的问题,事实上,在实际的代码中,技术名词的出现,往往就代表着它缺少了一个应有的模型。
比如,在业务代码里如果直接出现了 Redis:
public Book getByIsbn(String isbn) {
Book cachedBook = redisBookStore.get(isbn);
if (cachedBook != null) {
return cachedBook;
}
Book book = doGetByIsbn(isbn);
redisBookStore.put(isbn, book);
return book;
}
通常来说,这里真正需要的是一个缓存。Redis 是缓存这个模型的一个实现:
public Book getByIsbn(String isbn) {
Book cachedBook = cache.get(isbn);
if (cachedBook != null) {
return cachedBook;
}
Book book = doGetByIsbn(isbn);
cache.put(isbn, book);
return book;
}
再进一步,缓存这个概念其实也是一个技术术语,从某种意义上说,它也不应该出现在业务代码中。这方面做得比较好的是 Spring。使用 Spring 框架时,如果需要缓存,我们通常是加上一个 Annotation(注解):
@Cacheable("books")
public Book getByIsbn(String isbn) {
...
}
程序员之所以喜欢用技术名词去命名,一方面是因为,这是大家习惯的语言,另一方面也是因为程序员学习写代码,很大程度上是参考别人的代码,而行业里面优秀的代码常常是一些开源项目,而这些开源项目往往是技术类的项目。**在一个技术类的项目中,这些技术术语其实就是它的业务语言。但对于业务项目,这个说法就必须重新审视了。**如果这个部分的代码确实就是处理一些技术,使用技术术语无可厚非,但如果是在处理业务,就要尽可能把技术术语隔离开来。
用业务语言写代码
无论是不精准的命名也好,技术名词也罢,归根结底,体现的是同一个问题:对业务理解不到位。
编写可维护的代码要使用业务语言。怎么才知道自己的命名是否用的是业务语言呢?一种简单的做法就是,把这个词讲给产品经理,看他知不知道是怎么回事。
从团队的角度看,让每个人根据自己的理解来命名,确实就有可能出现千奇百怪的名字,所以,一个良好的团队实践是,建立团队的词汇表,让团队成员有信息可以参考。
团队对于业务有了共同理解,我们也许就可以发现一些更高级的坏味道,比如说下面这个函数声明:
public void approveChapter(long chapterId, long userId) {
...
}
这个函数的意图是,确认章节内容审核通过。这里有一个问题,chapterId 是审核章节的ID,这个没问题,但 userId 是什么呢?了解了一下背景,我们才知道,之所以这里要有一个 userId,是因为这里需要记录一下审核人的信息,这个 userId 就是审核人的 userId。
你看,通过业务的分析,我们会发现,这个 userId 并不是一个好的命名,因为它还需要更多的解释,更好的命名是 reviewerUserId,之所以起这个名字,因为这个用户在这个场景下扮演的角色是审核人(Reviewer)。
public void approveChapter(long chapterId, long reviewerUserId) {
...
}
从某种意义上来说,这个坏味道也是一种不精准的命名,但它不是那种一眼可见的坏味道,而是需要在业务层面上再进行讨论,所以,它是一种更高级的坏味道。
总结
以上讲了两个典型的命名坏味道:
- 不精准的命名
- 用技术术语命名
命名是软件开发中两件难事之一(另一个难事是缓存失效),不好的命名本质上是增加我们的认知成本,同样也增加了后来人(包括我们自己)维护代码的成本。
好的命名要体现出这段代码在做的事情,而无需展开代码了解其中的细节,这是最低的要求。再进一步,好的命名要准确地体现意图,而不是实现细节。更高的要求是,用业务语言写代码。
命名遵循的原则:
- 描述意图,而非细节。
- 面向接口编程,接口时稳定的,实现是易变的。
- 命名中出现技术名词,往往是它缺少了一个模型。
- 使用业务语言。
至此,我们已经对命名有了一个更深入的认识。下一讲,我们来说说国外那些经典的讲编码的书都不曾覆盖到的一个话题:英文命名。
如果今天的内容你只能记住一件事,那请记住:好的命名,是体现业务含义的命名。
乱用英语:站在中国人的视角来看英文命名
现在主流的程序设计语言都是以英语为基础的,且不说欧美人设计的各种语言,就连日本人设计的 Ruby、巴西人设计的 Lua,各种语法采用的也全都是英语。所以,想要成为一个优秀的程序员,会用英语写代码是必要的。
这里并不是说,程序员的英语一定要多好,但最低限度的要求是写出来的代码要像是在用英语表达。或许你听说过,甚至接触过国内的一些程序员用汉语拼音写代码,这就是一种典型的坏味道。鉴于现在的一些程序设计语言已经支持了 UTF-8 的编码格式,用汉语拼音写代码,还不如用汉字直接写代码
当然,这个坏味道实在是太低级了,我就不在这里深入讨论了。让我们来看看还有哪些可能会不经意间忽略的坏味道。
违反语法规则的命名
我们来看一段代码:
public void completedTranslate(final List<ChapterId> chapterIds) {
List<Chapter> chapters = repository.findByChapterIdIn(chapterIds);
chapters.forEach(Chapter::completedTranslate);
repository.saveAll(chapters);
}
初看之下,这段代码写得还不错,它要做的是将一些章节的信息标记为翻译完成。似乎函数名也能反映这个意思,但仔细一看你就会发现问题
因为 completedTranslate 并不是一个正常的英语函数名。从这个名字你能看出,作者想表达的是“完成翻译”,因为是已经翻译完了,所以,他用了完成时的 completed,而翻译是 translate。这个函数名就成了 completedTranslate。由此,你可以看到,作者已经很用心了,但遗憾的是,这个名字还是起错了。
一般来说,常见的命名规则是:类名是一个名词,表示一个对象,而方法名则是一个动词,或者是动宾短语,表示一个动作
以此为标准衡量这个名字,completedTranslate 并不是一个有效的动宾结构。如果把这个名字改成动宾结构,只要把“完成”译为 complete,“翻译”用成它的名词形式translation 就可以了。所以,这个函数名可以改成 completeTranslation:
public void completeTranslation(final List<ChapterId> chapterIds) {
List<Chapter> chapters = repository.findByChapterIdIn(chapterIds);
chapters.forEach(Chapter::completeTranslation);
repository.saveAll(chapters);
}
这并不是一个复杂的坏味道,但这种坏味道在代码中却时常可以见到,比如,一个函数名是 retranslation,其表达的意图是重新翻译,但作为函数名,它应该是一个动词,所以,正确的命名应该是 retranslate。
其实,只要你懂得最基本的命名要求,知道最基本的英语规则,就完全能够发现这里的坏味道。比如,判断函数名里的动词是不是动词,宾语是不是一个名词?这并不需要英语有多么好。自己实在拿不准的时候,你就把这个词放到字典网站中查一下,确保别用错词性就好。
对于大多数国内程序员来说,字典网站是我们的好朋友,是我们在写程序过程中不可或缺的一个好伙伴。不过,有些人使用字典网站也会很随意。
不准确的英语词汇
有一次,我们要实现一个章节审核的功能,一个同事先定义出了审核的状态:
public enum ChapterAuditStatus {
PENDING,
APPROVED,
REJECTED;
}
你觉得这段代码有问题吗?如果看不出来,一点都不奇怪。如果你用审核作为关键字去字典网站上搜索,确实会得到 audit 这个词。所以,审核状态写成 AuditStatus 简直是再正常不过的事情了。
然而,看到这个词的时候,我的第一反应就是这个词好像不太对。因为之前我实现了一个作品审核的功能,不过我写的定义是这样的:
public enum BookReviewStatus {
PENDING,
APPROVED,
REJECTED;
}
抛开前缀不看,同样是审核,一个用了 audit,一个用了 review。这显然是一种不一致。本着代码一致性的考虑,我希望这两个定义应该采用同样的词汇。
于是,我把 audit 和 review 同时放到了搜索引擎里查了一下。原来,audit 会有更官方的味道,更合适的翻译应该是审计,而 review 则有更多核查的意思,二者相比,review 更适合这里的场景。于是,章节的审核状态也统一使用了 review:
public enum ChapterReviewStatus {
PENDING,
APPROVED,
REJECTED;
}
相比之下,这个坏味道是一个高级的坏味道,英语单词用得不准确。但这个问题确实是国内程序员不得不面对的一个尴尬的问题,我们的英语可能没有那么好,体会不到不同单词之间的差异。
很多人习惯的做法就是把中文的词扔到字典网站,然后从诸多返回的结果中找一个自己看着顺眼的,而这也往往是很多问题出现的根源。这样写出来的程序看起来就像一个外国人在说中文,虽然你知道他在说的意思,但总觉得哪里怪怪的。
在这种情况下,最好的解决方案还是建立起一个业务词汇表,千万不要臆想。 一般情况下,我们都可以去和业务方谈,共同确定一个词汇表,包含业务术语的中英文表达。这样在写代码的时候,你就可以参考这个词汇表给变量和函数命名。
下面是一个词汇表的示例,从这个词汇表中你不难看出:一方面,词汇表给出的都是业务术语,同时也给出了在特定业务场景下的含义;另一方面,它也给出了相应的英文,省得你费劲心思去思考。当你遇到了一个词汇表中没有的术语怎么办呢?那就需要找出这个术语相应的解释,然后,补充到术语表里。
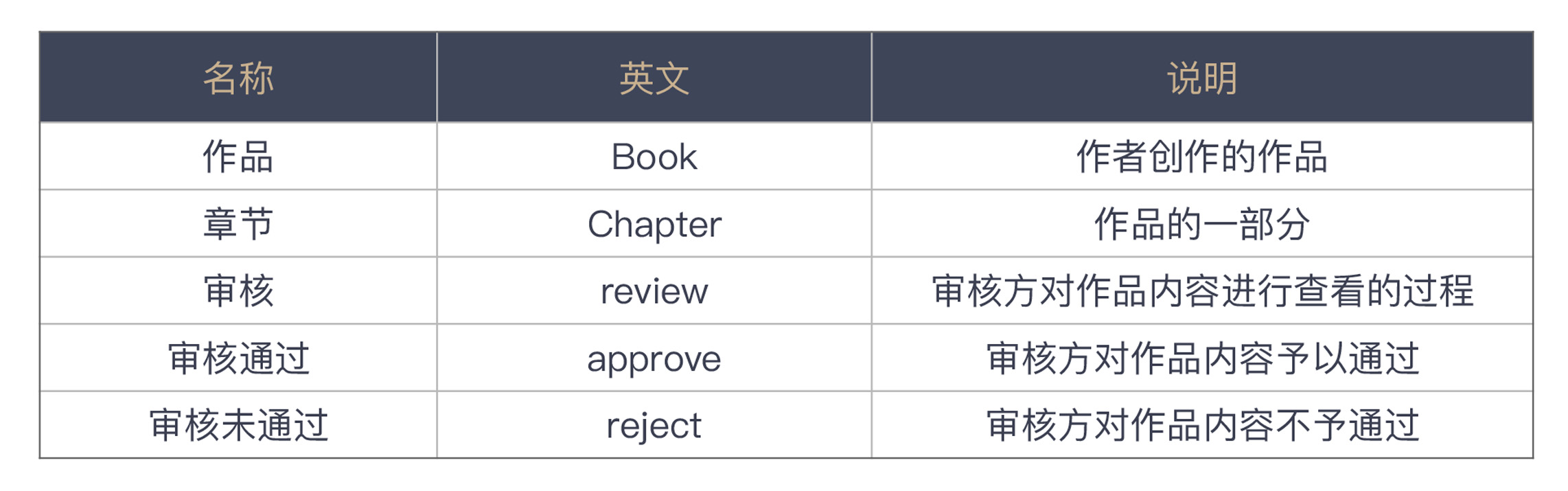
建立词汇表的另一个关键点就是,用集体智慧,而非个体智慧。你一个人的英语可能没那么好,但一群人总会找出一个合适的说法。
英语单词的拼写错误
我再给你看一段曾经让我迷惑不已的代码:
public class QuerySort {
private final SortBy sortBy;
private final SortFiled sortFiled;
...
}
初看这段代码时,我还想表扬代码的作者,他知道把查询的排序做一个封装,比起那些把字符串传来传去的做法要好很多。
但仔细看一下代码,我脑子里就冒出了一系列问号。sortFiled 是啥?排序文件吗?为啥用的还是过去式?归档?
被这段代码搞晕的我只好打开提交历史,找出这段代码的作者,向他求教。
我:这个字段是啥意思?
同事:这是排序的字段啊。
我:排序的字段?
同事:你看,这个查询排序类有两个字段,一个是排序的方式,升序还是降序,另一个
就是排序的字段。
我:字段这个单词是这么拼吗?
同事:不是吗?哦!是 field,拼错了,拼错了。
你看,是他把单词拼错了。
其实,偶尔的拼写错误是不可避免的,这就像我们写文章的时候,出现错别字也是难免的。之所以要在这个专栏中把拼写错误作为一种独立的坏味道,是因为在很多国内程序员写的程序中,见到的拼写错误比例是偏高的。
在这个故事里面,我都已经当面指出了问题,这个同事甚至都没有第一时间意识到自己的拼写是错误的,这其实说明了一种尴尬的现状:很多程序员对英语的感觉并没有那么强。
事实上,这个同事不止一次在代码里出现拼写错误了,一些拼写错误是很直白的,一眼就能看出来,所以,通常在代码评审的时候就能发现问题。这次的拼写错误刚好形成了另外一个有含义的单词,所以,我也被困住了。
对今天的程序员来说,工具已经很进步了,像 IntelliJ IDEA 这样的 IDE 甚至可以给你提示代码里有拼写错误(typo),不少支持插件的工具也都有自己的拼写检查插件,比如Visual Studio Code 就有自己的拼写检查插件。在这些工具的帮助之下,我们只要稍微注意一下,就可以修正很多这样低级的错误。
这一讲的内容几乎是完全针对国内程序员的。对于国外程序员来说,他们几乎不会犯这些错误。英语是程序员无论如何也绕不过去的一关,越是想成为优秀程序员,越要对英语有良好的感觉。当然,这里并不强求所有人的英语都能达到多好的程度,至少看到一些明显违反英语规则的代码,自己应该有能力看出来。
总结
以上讲了几个英语使用不当造成的坏味道:
- 违反语法规则的命名;
- 不准确的英语词汇;
- 英语单词的拼写错误。
这是国内程序员因为语言关系而造成的坏味道,英语是目前软件开发行业的通用语言,一个程序员要想写好程序,要对程序中用到的英语有一个基本的感觉,能够发现代码中的这些坏味道。
其实,还有一些常见的与语言相关的坏味道,因为比较初级,我只放在这里给你提个醒,比如:
- 使用拼音进行命名;
- 使用不恰当的单词缩写(比如,多个单词的首字母,或者写单词其中的一部分)。
我们还讨论了如何从实践层面上更好地规避这些坏味道:
- 制定代码规范,比如,类名要用名词,函数名要用动词或动宾短语;
- 要建立团队的词汇表。
- 要经常进行代码评审。
命名之所以如此重要,因为它是一切代码的基础。就像写文章一样,一个错别字满天飞的文章,很难让人相信它会是一篇好的文章,所以,命名的重要性是如何强调都不为过的。
记住一句话,编写符合英语语法规则的代码。
重复代码:简单需求到处修改,怎么办?
记得我刚开始工作的时候,有人开玩笑说,编程实际上就是 CVS(CVS 是当时流行的一个版本控制工具,相当于今天的 Git),也就是 Ctrl+C、Ctrl+V、Ctrl+S,或许你已经听出来了,这是在调侃很多程序员写程序依靠的是复制粘贴。
时至今日,很多初级程序员写代码依然规避不了复制粘贴,基本的做法就是把一段代码复制过来,改动几个地方,然后,跑一下没有太大问题就万事大吉了。殊不知,这种做法就是在给未来挖坑。
通常情况下,只要这些复制代码其中有一点逻辑要修改,就意味着所有复制粘贴的地方都要修改。所以,我们在实际的项目中,常常看见这样的情况:明明是一个简单的需求,你却需要改很多的地方,需要花费很长的时间,结果无论是项目经理,还是产品经理,对进度都很不满意。
更可怕的是,只要你少改了一处,就意味着留下一处潜在的问题。问题会在不经意间爆发出来,让人陷入难堪的境地。
复制粘贴是最容易产生重复代码的地方,所以,一个最直白的建议就是,不要使用复制粘贴。真正应该做的是,先提取出函数,然后,在需要的地方调用这个函数。
其实,复制粘贴的重复代码是相对容易发现的,但有一些代码是有类似的结构,这也是重复代码,有些人对这类坏味道却视而不见。
重复的结构
我们看一下下面的几段代码:
@Task
public void sendBook() {
try {
this.service.sendBook();
} catch (Throwable t) {
this.notification.send(new SendFailure(t)));
throw t;
}
}
@Task
public void sendChapter() {
try {
this.service.sendChapter();
} catch (Throwable t) {
this.notification.send(new SendFailure(t)));
throw t;
}
}
@Task
public void startTranslation() {
try {
this.service.startTranslation();
} catch (Throwable t) {
this.notification.send(new SendFailure(t)));
throw t;
}
}
这三段函数业务的背景是:一个系统要把作品的相关信息发送给翻译引擎。所以,结合着代码,我们就不难理解它们的含义,sendBook 是把作品信息发出去,sendChapter 就是把章节发送出去,而 startTranslation 则是启动翻译。
这几个业务都是以后台的方式在执行,所以,它们的函数签名上增加了一个 Task 的Annotation,表明它们是任务调度的入口。然后,实际的代码执行放到了对应的业务方法上,也就是 service 里面的方法。
这三个函数可能在许多人看来已经写得很简洁了,但是,这段代码的结构上却是有重复的,请把注意力放到 catch 语句里。
之所以要做一次捕获(catch),是为了防止系统出问题无人发觉。捕获到异常后,我们把出错的信息通过即时通讯工具发给相关人等,代码里的 notification.send 就是发通知的入口。相比于原来的业务逻辑,这个逻辑是后来加上的,所以,这段代码的作者不厌其烦地在每一处修改了代码。
我们可以看到,虽然这三个函数调用的业务代码不同,但它们的结构是一致的,其基本流程可以理解为:
- 调用业务函数
- 如果出错,发通知
当你能够发现结构上的重复,我们就可以把这个结构提取出来。从面向对象的设计来说,就是提出一个接口,就像下面这样:
private void executeTask(final Runnable runnable) {
try {
runnable.run();
} catch (Throwable t) {
this.notification.send(new SendFailure(t)));
throw t;
}
}
有了这个结构,前面几个函数就可以用它来改写了。对于支持函数式编程的程序设计语言来说,可以用语言提供的便利写法简化代码的编写,像下面的代码就是用了 Java 里的方法引用(Method Reference):
@Task
public void sendBook() {
executeTask(this.service::sendBook);
}
@Task
public void sendChapter() {
executeTask(this.service::sendChapter);
}
@Task
public void startTranslation() {
executeTask(this.service::startTranslation);
}
经过这个例子的改写,如果再有一些通用的结构调整,比如,在任务执行前后要加上一些日志信息,这样的改动就可以放到 executeTask 这个函数里,而不用四处去改写了。
这个例子并不复杂,关键点在于,能不能发现结构上的重复。因为相比于直接复制的代码,结构上的重复看上去会有一些迷惑性。比如,在这个例子里,发送作品信息、发送章节、启动翻译看起来是三件不同的事,很难让人一下反应过来它也是重复代码。
一般来说,参数是名词,而函数调用,是动词。我们传统的程序设计教育中,对于名词是极度重视的,但我们必须认识到一点,动词也扮演着重要的角色,尤其是在函数式编程兴起之后。那你就需要知道,动词不同时,并不代表没有重复代码产生。
理解到这一点,我们就容易发现结构上的相似之处。比如在上面的例子中,发送作品信息、发送章节、启动翻译之所以看上去是三件不同的事,只是因为它们的动词不同,但是除了这几个动词之外的其它部分是相同的,所以,它们在结构上是重复的。
做真正的选择
我们再来看一段代码:
if (user.isEditor()) {
service.editChapter(chapterId, title, content, true);
} else {
service.editChapter(chapterId, title, content, false);
}
这是一段对章节内容进行编辑的代码。这里有一个业务逻辑,章节只有在审核通过之后,才能去做后续的处理,比如,章节的翻译。所以,这里的 editChapter 方法最后那个参数表示是否审核通过。
在这段代码里面,目前的处理逻辑是,如果这个章节是由作者来编辑的,那么这个章节是需要审核的,如果这个章节是由编辑来编辑的,那么审核就直接通过了,因为编辑本身同时也是审核人。不过,这里的业务逻辑不是重点,只是帮助你理解这段代码。
问题来了,这个 if 选择的到底是什么呢?
相信你和我一样,第一眼看到这段代码的感觉一定是,if 选择的一定是两段不同的业务处理。但只要你稍微看一下,就会发现,if 和 else 两段代码几乎是一模一样的。在经过仔细地“找茬”之后,才能发现,原来是最后一个参数不一样。
只有参数不同,是不是和前面说的重复代码是如出一辙的?没错,这其实也是一种重复代码。
只不过,这种重复代码通常情况下是作者自己写出来的,而不是粘贴出来的。因为作者在写这段代码时,**脑子只想到 if 语句判断之后要做什么,而没有想到这个 if 语句判断的到底是什么。**但这段代码客观上也造就了重复。
写代码要有表达性。把意图准确地表达出来,是写代码过程中非常重要的一环。显然,这里的 if 判断区分的是参数,而非动作。所以,我们可以把这段代码稍微调整一下,会让代码看上去更容易理解:
boolean approved = user.isEditor();
service.editChapter(chapterId, title, content, approved);
请注意,这里我把 user.isEditor() 判断的结果赋值给了一个 approved 的变量,而不是直接作为一个参数传给 editChapter,这么做也是为了提高这段代码的可读性。因为editChapter 最后一个参数表示的是这个章节是否审核通过。通过引入 approved 变量,我们可以清楚地看到,一个章节审核是否通过的判断条件是“用户是否是一个编辑”,这种写法会让代码更清晰。
如果将来审核通过的条件改变了,变化的点全都在 approved 的这个变量的赋值上面。如果你追求更有表达性的做法,甚至可以提取一个函数出来,这样,就把变化都放到这个函数里了,就像下面这样:
boolean approved = isApproved(user);
service.editChapter(chapterId, title, content, approved);
private boolean isApproved(final User user) {
return user.isEditor();
}
为了说明问题,我特意选择了一段简单的代码,if 语句的代码块里只有一个语句。在实际的工作中,if 语句没有有效地去选择目标是经常出现的,有的是参数列表比较长,有的是在 if 的代码块里有多个语句。
所以,**只要你看到 if 语句出现,而且 if 和 else 的代码块长得又比较像,多半就是出现了这个坏味道。**如果你不想所有人都来玩“找茬”游戏,赶紧消灭它。
重复是一个泥潭,对于程序员来说,时刻提醒自己不要重复是至关重要的。在软件开发里,有一个重要的原则叫做 Don’t Repeat Yourself(不要重复自己,简称 DRY),我在《软件设计之美》中也讲到过它,而更经典的叙述在《程序员修炼之道》中。
在一个系统中,每一处知识都必须有单一、明确、权威地表述。
Every piece of knowledge must have a single, unambiguous, authoritative
representation within a system.
写代码要想做到 DRY,一个关键点是能够发现重复。发现重复,一种是在泥潭中挣扎后,被动地发现,还有一种是提升自己识别能力,主动地发现重复。这种主动识别的能力,其实背后要有对软件设计更好的理解,尤其是对分离关注点的理解。
总结
以上讲到了几个典型的重复代码坏味道:
- 复制粘贴的代码;
- 结构重复的代码;
- if 和 else 代码块中的语句高度类似;
很多重复代码的产生通常都是从程序员偷懒开始的,而这些程序员的借口都是为了快,却为后续工作买下更多地隐患,真正的“欲速而不达”。
复制粘贴的代码和结构重复的代码,虽然从观感上有所差异,但本质上都是重复,只不过,一个是名词的微调,一个是动词的微调。
程序员千万不要复制粘贴,如果需要复制粘贴,首先应该做的是提取一个新的函数出来,把公共的部分先统一掉。
if 和 else 的代码块中的语句高度类似,通常是程序员不经意造成的,但这也是对于写代码没有高标准要求的结果。让 if 语句做真正的选择,是提高代码表达准确性的重要一步。
作为一个精进中的程序员,我们一定要把 DRY 原则记在心中,时时刻刻保持对“重复”的敏感度,把各种重复降到最低。
记住一句话:不要重复自己,不要复制粘贴





