
一、前言
1.1.什么是时序数据库
首先介绍一下什么是时序数据,时序数据是基于时间的一系列的数据。在有时间的坐标中将这些数据点连成线,往过去看可以做成多纬度报表,揭示其趋势性、规律性、异常性;往未来看可以做大数据分析,机器学习,实现预测和预警。
时序数据库就是存放时序数据的数据库,并且需要支持时序数据的快速写入、持久化、多纬度的聚合查询等基本功能。
对比传统数据库仅仅记录了数据的当前值,时序数据库则记录了所有的历史数据。同时时序数据的查询也总是会带上时间作为过滤条件。
1.2.时序数据库的特点
数据写入
- 写入平稳、持续、高并发高吞吐:时序数据的写入是比较平稳的,这点与应用数据不同,应用数据通常与应用的访问量成正比,而应用的访问量通常存在波峰波谷。时序数据的产生通常是以一个固定的时间频率产生,不会受其他因素的制约,其数据生成的速度是相对比较平稳的。
- 写多读少:时序数据上95%-99%的操作都是写操作,是典型的写多读少的数据。这与其数据特性相关,例如监控数据,你的监控项可能很多,但是你真正去读的可能比较少,通常只会关心几个特定的关键指标或者在特定的场景下才会去读数据。
- 实时写入最近生成的数据,无更新:时序数据的写入是实时的,且每次写入都是最近生成的数据,这与其数据生成的特点相关,因为其数据生成是随着时间推进的,而新生成的数据会实时的进行写入。数据写入无更新,在时间这个维度上,随着时间的推进,每次数据都是新数据,不会存在旧数据的更新,不过不排除人为的对数据做订正。
数据查询和分析
- 按时间范围读取:通常来说,你不会去关心某个特定点的数据,而是一段时间的数据。
- 最近的数据被读取的概率高
- 历史数据粗粒度查询的概率搞
- 多种精度查询
- 多维度分析
数据存储
-
数据量大:拿监控数据来举例,如果我们采集的监控数据的时间间隔是1s,那一个监控项每天会产生86400个数据点,若有10000个监控项,则一天就会产生864000000个数据点。在物联网场景下,这个数字会更大。整个数据的规模,是TB甚至是PB级的。
-
冷热分明:时序数据有非常典型的冷热特征,越是历史的数据,被查询和分析的概率越低。
-
具有时效性:时序数据具有时效性,数据通常会有一个保存周期,超过这个保存周期的数据可以认为是失效的,可以被回收。一方面是因为越是历史的数据,可利用的价值越低;另一方面是为了节省存储成本,低价值的数据可以被清理。
-
多精度数据存储:在查询的特点里提到时序数据出于存储成本和查询效率的考虑,会需要一个多精度的查询,同样也需要一个多精度数据的存储。
1.3.时序数据库适合的场景
所有有时序数据产生,并且需要展现其历史趋势、周期规律、异常性的,进一步对未来做出预测分析的,都是时序数据库适合的场景。
1.4.时序数据库的数据模型
时间序列数据可以分成两部分:
- 序列 :就是标识符(维度),主要的目的是方便进行搜索和筛选
- 数据点:时间戳和数值构成的数组
- 行存:一个数组包含多个点,如 [{t: 2017-09-03-21:24:44, v: 0.1002}, {t: 2017-09-03-21:24:45, v: 0.1012}]
- 列存:两个数组,一个存时间戳,一个存数值,如[ 2017-09-03-21:24:44, 2017-09-03-21:24:45], [0.1002, 0.1012]
一般情况下:列存能有更好的压缩率和查询性能
1.5.时序数据库的基本概念
metric:度量,相当于关系型数据库中的table。
data point: 数据点,相当于关系型数据库中的row。
timestamp:时间戳,代表数据点产生的时间。
field: 度量下的不同字段。比如位置这个度量具有经度和纬度两个field。一般情况下存放的是会随着时间戳的变化而变化的数据。
tag: 标签,或者附加信息。一般存放的是并不随着时间戳变化的属性信息。timestamp加上所有的tags可以认为是table的primary key。
二、influxDB简介
influxDB在Github上的地址:https://github.com/influxdata/influxdb
2.1.influxDB是什么
InfluxDB是一个由InfluxData开发的开源时序型数据库。它由Go写成,着力于高性能地查询与存储时序型数据。InfluxDB被广泛应用于存储系统的监控数据,IoT(物联网)行业的实时数据等场景。
2.2.influxDB的特点
- InfluxDB在技术实现上充分利用了Go语言的特性,无需任何外部依赖即可独立部署。
- InfluxDB提供了一个类似于SQL的查询语言并且一系列内置函数方便用户进行数据查询。
- InfluxDB存储的数据从逻辑上由 Measurement, tag组以及 field组以及一个时间戳组成的:
- Measurement: 由一个字符串表示该条记录对应的含义。比如它可以是监控数据"cpu_load",也可以是测量数据"average_temperature"
- tag组: 由一组键值对组成,表示的是该条记录的一系列属性信息。同样的measurement数据所拥有的tag组不一定相同,它是无模式的(Schema-free)。tag信息是默认被索引的。
- field组:也是由一组键值对组成,表示的是该条记录具体的value信息(有名称)。field组中可定义的value类型包括:64位整型,64位浮点型,字符串以及布尔型。Field信息是无法被索引的。
- 时间戳:就是该条记录的时间属性。如果插入数据时没有明确指定时间戳,则默认存储在数据库中的时间戳则为该条记录的入库时间。
- InfluxDB支持基于HTTP的数据插入与查询。同时也接受直接基于TCP或UDP协议的连接。
- InfluxDB允许用户定义数据保存策略(Retention Policies)来实现对存储超过指定时间的数据进行删除或者降采样。
2.3.influxDB的关键概念
基本概念
InfluxDB 和传统数据库(如:MySQL)的一些区别
| InfluxDB | 传统数据库中的概念 |
|---|---|
| database | 数据库 |
| measurement | 数据库中的表 |
| points | 表里面的一行数据 |
特有概念
-
tag–标签,在 InfluxDB 中,tag 是一个非常重要的部分,表名+tag 一起作为数据库的索引,是“key-value”的形式
-
field–数据,field 主要是用来存放数据的部分,也是“key-value”的形式
-
timestamp–时间戳,作为时序型数据库,时间戳是 InfluxDB 中最重要的部分,在插入数据时可以自己指定也可留空让系统指定
说明:在插入新数据时,tag、field 和 timestamp 之间用空格分隔
-
series–序列,所有在数据库中的数据,都需要通过图表来展示,而这个 series 表示这个表里面的数据,可以在图表上画成几条线。具体可以通过
SHOW SERIES FROM "表名"进行查询 -
Retention policy–数据保留策略,可以定义数据保留的时长,每个数据库可以有多个数据保留策略,但只能有一个默认策略
-
Point–点,表示每个表里某个时刻的某个条件下的一个 field 的数据,因为体现在图表上就是一个点,于是将其称为 point。Point 由时间戳(time)、数据(field)、标签(tags)组成
| Point 属性 | 传统数据库中的概念 |
|---|---|
| time | 每个数据记录时间,是数据库中的主索引 (会自动生成) |
| fields | 表中的列(没有索引的属性)也就是记录的值:温度, 湿度 |
| tags | 表中的索引:地区,海拔 |
2.4.influxDB端口
- 8083:Web admin 管理服务的端口, http://localhost:8083
- 8086:HTTP API 的端口
- 8088:集群端口
三、influxDB安装
3.1.Linux上安装
3.2.Windows上安装
下载地址:https://dl.influxdata.com/influxdb/releases/influxdb-1.8.3_windows_amd64.zip
3.3.docker上安装
docker pull influxdb
四、influxDB基本使用(以Windows为例)
4.1.启动
# 在cmd中进入到influxDB目录输入以下命令启动influxDB
influxd.exe -config influxdb.conf
# 启动客户端,如果没有修改过conf文件,那么则不用在后面指定端口
influx.exe -port 8081
# 格式化时间方式启动,如果不加-precision rfc3339启动
# 当在控制台执行SQL时,显示的数据的timestemp是以ns为单位的时间戳格式
# 而加上之后,则是以正常的yyyy-MM-ddThh:mm:ssZ这种UTC格式
influx -host localhost -port 9909 -precision rfc3339
4.2.用户
#显示所有用户
show users
#创建用户
create user "username" with password 'password'
#创建管理员权限用户
create user "username" with password 'password' with all privileges
#修改用户密码
set password for username = "password"
#删除用户
drop user "username"
4.3.权限
#查看权限
show grants for username
#赋予管理员权限
grant all privileges to username
#取消权限
revoke all on mydb from username
4.4.登录账号
认证策略需要在配置文件中打开[http]下的auth-enabled = true
auth
然后输入账号密码
4.5.数据库操作
#查看所有数据库
show databases
#创建数据库
create database "testDB"
#使用数据库
use testDB
4.6.表
#显示所有表
show measurements
#创建表
insert test,host=127.0.0.1,monitor_name=test count=1
#删除表
drop measurement "measurement_name"
4.7插入数据
insert weather,altitude=5000,area=北 humidity=3,temperature=23 1599630284710054000
- measurement(表名): weather
- tags(类似索引): altitude、area。是String类型
- fields: temperature、humidity。是字符串、数字类型
- influx默认时间是纳秒(ns),即19位时间戳
4.16.查看表名
show measurements
4.17.查看数据
# 操作与mysql类似
select * from weather where time >=1599630284710ms
select * from weather where time >= '2018-11-23 14:30:39' and time <= '2018-11-23 14:32:32' tz('Asia/Shanghai')
# 涉及时间查询使用时间戳,避免时区问题
4.18.查看策略
show retention policies on 'weather'
4.19.创建策略
create retention policy "rp_test" on "testDB" duration 30d replication 1 default
-
rp_test: 策略名
-
testDB:数据库名
-
30d:数据保存时间,30天之前的数据将被删除
-
replication 1: 副本个数
-
default: 设为默认策略
| duration | shardGroupDuration |
|---|---|
| <2days | 1hour |
| >=2days and <=6months | 1day |
| >6months | 7days |
4.20.修改策略
alter retention policy "rp_test" on "testDB" duration 1d replication 1
4.21.删除策略
drop retention policy " rp_test" on " testDB"
4.22.查询连续查询
SHOW CONTINUOUS QUERIES
- 这条命令得在命令行下输入,在web管理界面不能显示。
- QUERIES需要大写
4.23.创建新的Continuous Queries
create continuous query cq_30m on testDB begin select mean(temperature) into weather30m from weather group by time(30m) end
-
cq_30m:连续查询的名字
-
testDB:具体的数据库名
-
mean(temperature): 算平均温度
-
weather: 当前表名
-
weather30m: 存新数据的表名
-
30m:时间间隔为30分钟
4.24.删除Continuous Queries
DROP CONTINUOUS QUERY <cq_name> ON <database_name>
五、常见问题
(1)数据迁移
1.备份元数据
influxd backup -host locahost:8088 /pzx/influx_db_backuo
2.备份数据库
influxd backup -database <database_name> -host localhost:8088 /pzx/influx_db_backup
3.在目标服务器上恢复元数据
influxd restore -metadir /var/lib/influxdb/meta/ /pzx/influx_db_backuo
4.在目标服务器上恢复数据库
influxd restore -database <database_name> -datadir /var/lib/influxdb/data /pzx/influx_db_backup
将备份的数据恢复到新库中
influxd restore -portable -db <old_database_name> -newdb <new_database_name> /pzx/influx_db_backup
5.修改权限
chown -R influxdb:influxdb /var/lib/influxdb
修改权限是必要的步骤,如果不修改权限,可能导致influxdb不能以服务启动,日志中会显示无权限异常。
6.重启influxdb
service influxdb stop
service influxdb start
(2)时区问题
因为influxdb中的默认时区使用的是UTC(世界协调时间),相较于GMT(中国标准时间)而言,会有8小时的时差,所以往influxdb中存放数据时,需要考虑到该问题;如果说,往influxdb中存入的时间为GMT时间,那么当你使用influxdb中的group by time(1h | 1d | 1w)时,会导致分组查询出的数据与预期不符。例如:
select * from test group by time(1d)
这样查查询出来的数据,时间划分不是以0点为分界线,而是16点为分界线,所以说会导致分组错误,数据有问题。
那么有方法可以解决该问题吗?
- 使用程序进行手动分组
- 使用influxdb中tz
上面两种方式,主要来说第二种,使用tz关键字来进行时区转换,其使用方式为:
select * from test group by time(1d) tz('Asia/Shanghai')
但是,如果说你在influxdb中直接执行该语句,那么可能会出现一个问题,控制台中会出来一下错误:
unable to find time zone Asia/Shanghai
找不到时区 亚洲/上海
该问题的错误原因为:influx是由go语言写成,如果说需要时区转换,则需要go语言的环境,而influxdb是没有给你安装go语言的环境,所以需要手动安装,以下介绍在windows中和linux中安装步骤
安装步骤
Windows
- 下载安装go语言环境,下载下来后,一直下一步就好了。
-
安装完成后,还需要配置go语言的环境
-
主要需要配置GOROOT和path
- 新建GOROOT,并将其value指向其的安装路径
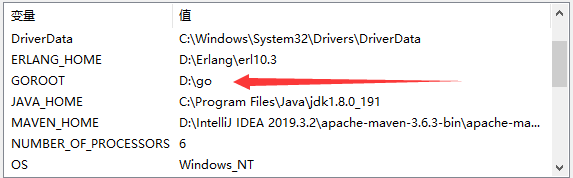
- 在Path中新增一条,其值为
%GOROOT%\bin
-
可选配置为GOPATH,这个是指向go的工作路径
-
-
配置完成后,在cmd中输入
go version查看环境是否配置成功 -
配置成功后,重启influxdb(尽量重启电脑,有时候只重启infludb,还是会提示找不到时区)
-
然后在influx中,执行上述语句,会发现不报错了,那就代表go语言环境配置成功。
CentOS7.6
方法一、yum安装
这种方法简单方便,而且安装的go版本也是最新版本,所以不必担心自动安装版本过低的问题。
[root@database /]# yum install golang
但是安装过程中可能会出现 没有可用软件包 golang 的情况,这是因为缺少 EPEL源 ,所以软件仓库中找不到安装的软件包,只要先安装一下erel源即可。
[root@database /]# yum install epel-release
安装完成后查看go版本号,成功显示就表示安装成功。
[root@database /]# go version
go version go1.13 linux/amd64
方法二、二进制包安装
安装包在官网可以下载。
由于之前安装了go1.13,所以我下载的是go1.12的包,以进行区分。
[root@database /]# wget -P /var/download https://dl.google.com/go/go1.12.10.linux-amd64.tar.gz
然后解压到 /usr/lib 目录,这里跟之前安装的版本所在目录相同,但是需要将之前安装的go文件夹名称改成'golang-1.13',以免产生冲突。
[root@database /]# tar -zxf /var/download/go1.12.10.linux-amd64.tar.gz -C /usr/lib/
然后将解压的go文件夹名改成'golang',进行一个简单的版本切换,再执行查看版本号的指令,发现变成了1.12版本。
[root@database /]# go version
go version go1.12.10 linux/amd64
配置环境变量
通过编辑 /etc/profile 文件配置环境变量。
[root@database /]# vim /etc/profile
在文件的末尾添加如下代码:
export GOROOT=/usr/lib/golang
export GOPATH=/var/goproject
export PATH=$PATH:$GOROOT/bin
[root@database /]# source /etc/profile
其中工作路径为 '/var/goproject' ,即我们编写的代码放到这个目录下面运行。
这样golang的环境就搭建好了,可以通过以下指令查看环境参数。
[root@database /]# go env